
Performance Considerations Using the Gosu Dot Notation
I have been using Guidewire Gosu for 12 years, and little did I know about the expense of using a simple dot until I invested time and looked deeper. In this blog, we will break down what happens when we use the brief dot notation. So whether developing or maintenance is on your mind, strap in and get some popcorn because here we go.
Entity Lookups
First Dot
We’ll start with a simple query to play with a record within Guidewire PolicyCenter.
var period = Query.make(PolicyPeriod).select().FirstResult
print(period.PolicyNumber)This SQL uses a Gosu query to get the ID, making sure it is not retired
SELECT /* KeyTable:pc_policyperiod; */ gRoot.ID col0
FROM pc_policyperiod gRoot
WHERE gRoot.Retired = 0We can tell this is a Gosu query because of the prefix to the root (e.g. g[osu]Root)
A Bean query follows to retrieve the entity so we can print the PolicyNumber
SELECT /* Entity:pc_policyperiod; */ bRoot.ID col0, [column list left out for brevity]
FROM pc_policyperiod bRoot WHERE bRoot.ID = 1We can tell this is a bean query because of the prefix to the root (e.g. b[ean]Root)
Once the bean is retrieved, it is turned into an entity and stored in global cache, so the next time you reference PolicyPeriod ID, the cache finds it.
Second Dot
Another example for an entity lookup but on a different entity
print(period.Policy.Account.AccountNumber) Notice we are going through 2 dot levels (Policy then Account)
To achieve this, Guidewire uses two more bean queries.
SELECT /* Entity:pc_policy; */ bRoot.ID col0, [column list left out for brevity]
FROM pc_policy bRoot WHERE bRoot.ID = 2
SELECT /* Entity:pc_account; */ bRoot.ID col0, [column list left out for brevity]
FROM pc_account bRoot WHERE bRoot.ID = 3Each time we reference a new entity, a query runs to retrieve that entity, caching along the way. Entity staleness is out of scope for this blog. Please see my other blog (How to Write Performant Queries) to learn more.
While this makes sense to have the data readily available, I think it helps to understand how it happens.
Array Lookups
We saw what happens when retrieving a value directly from an entity, but what about retrieving a list from an entity? For example, the list of account contacts on an account:
print(period.Policy.Account.AccountContacts)Since we already did two bean queries for Policy and Account, they are in the cache, no database access needed for them. But to retrieve the array of AccountContacts, an array query is needed to grab the non retired AccountyContact IDs linked to the Account (8 returned).
SELECT /* KeyTable:pc_accountcontact, ParentTable:pc_account:; */ aRoot.ID col0
FROM pc_accountcontact aRoot WHERE aRoot.Account = 1 [left out for brevity]We can tell this is an array query because of the prefix to the root (e.g. a[rray]Root)
Then a bean query retrieves the Contact ID’s from the AccountContacts (8 returned).
SELECT /* Entity:pc_accountcontact; */ bRoot.ID col0, bRoot.Contact col13
FROM pc_accountcontact bRoot WHERE bRoot.ID IN (?,?,?,?,?,?,?,?)And finally, eight more bean queries are needed to print the contact’s DisplayName
SELECT /* Entity:pc_contact; */ bRoot.AdjudicatorLicense col0, [column list left out for brevity]
FROM pc_contact bRoot WHERE bRoot.ID = ?Why did we pull back the entire entity to print the default DisplayName? Since we did not specify what we wanted to print, Gosu pulls the whole entity to invoke the AccountContact.en DisplayName processor. My blog on Performant Queries gets into the details, just remember the default toString for any entity uses the .en file. Since Gosu does not know which references are used within the .en file, it returns the entire entity just in case.
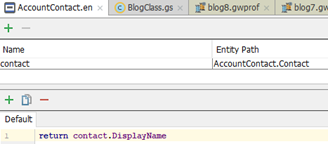
Splat Lookups
Finally, let’s look at what Guidewire Gosu splat (*) does. Splat is a powerful (yet expensive) operation to flatten an array allowing accessibility to properties within the array. For example, all Coverable States within each Coverable:
print(period.Policy.LatestBoundPeriod.AllCoverables*.CoverableState) 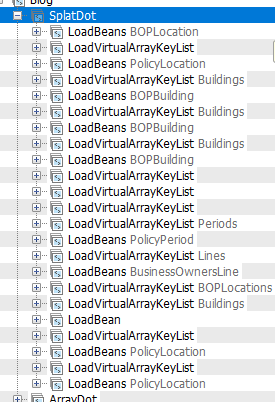
Using the same principles we already discussed, each Coverable entity is fully hydrated and loaded into memory, then each CoverableState for each Coverables is also fully hydrated and loaded into memory. It’s important to understand the sheer volume of data retrieved and stored, even though I only want to print the CoverableState.
Practical Uses
Now that we have a better understanding of the ORM black box, let’s put this into practical use.
While looking into OOTB code, I noticed quite a few places that need the primary contact on the policy. The path to this is quite long and can be found using:
period.Policy.Account.AccountHolder.AccountContact.Contact.PersonThat is six dots and many entities deep. Imagine, for a minute, if we could reduce this down to a simple query to grab the needed contact.
I have to say, it took me a while to figure this one out; and I learned some things along the way which I will share. But first, let’s take a look at the query load to perform the above.
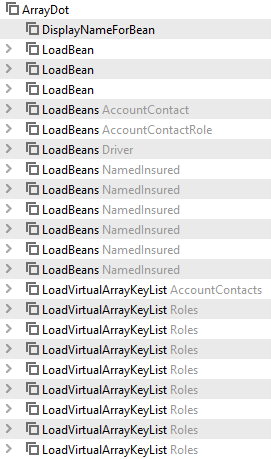
Notice how many inner queries are needed to get access to the Contact entity. The only good thing about doing this is that they are all entity queries and stored in cache, so the next time those objects are needed, it finds them.
Breaking this operation down, we need to investigate the data dictionary to gain some critical insights.

Notice the last property in the picture, AccountHolderContact. It tells us that it is already denormalized which reduces the query by three dots. But for the sake of this article, we are going to optimize the query to only what we need.
If we have an account number, we can go right to the Account table and join the Account Contact table. From there, we can reference the denormalized column using QuerySelectColumn turning an entity query into a row query.
uses gw.api.database.Query
uses gw.api.database.QuerySelectColumns
uses gw.api.database.Relop
uses gw.api.path.Paths
uses gw.pl.persistence.core.Key
var row = Query.make(PolicyPeriod)
.compare(PolicyPeriod#PublicID, Equals, "pc:1")
.join(PolicyPeriod#Policy)
.join(Policy#Account)
.compare(Account#AccountNumber, Relop.Equals, "C000143542")
.select({QuerySelectColumns.pathWithAlias("AHC", Paths.make(PolicyPeriod#Policy,
Policy#Account, Account#AccountHolderContact))})
.AtMostOneRowNote: Something which took me a while to figure out, is the traversal through the graph. In the Path statement above, we need to traverse from PolicyPeriod to Account.
Now that we have the needed ID, we simply load the Contact bean, which gives us the entity.
With this, you can reference any property on the contact as long as it is not part of a FK reference.
gw.transaction.Transaction.runWithNewBundle(bundle -> {
var contact = (bundle.loadBean(row.getColumn("AHC") as Key) as Contact)
print(contact.DisplayName)
print(contact.EmailAddress1)
}, "su")Here is the significantly reduced query from Profiler.
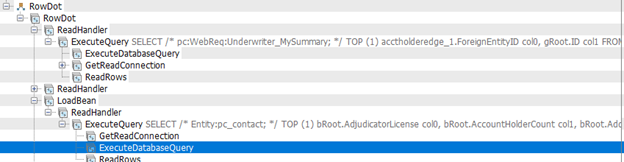
Conclusion
As we have seen, the dot notation is elementary to use, but you should be conscious about what you are doing when accessing items through the entity graph. It might not be obvious when developing but will undoubtedly impact your Guidewire application maintenance costs. For example, if you only need minimal information from an entity a few dots away, it may be more performant to build row queries and reduce the overall data. The side benefit is that it reduces data traffic and memory since these items are not stored in cache.
Troy Stauffer
Senior Software Architect
Watch or read our other posts at Kimputing Blogs. You’ll find everything from Automated testing to CenterTest, Guidewire knowledge to general interest. We’re trying to help share our knowledge from decades of experience.





